AP统计置信区间要凉?假设检验要跪?

快要考试了,脑子里对统计各种概念还是一团浆糊?问答题完全不知道在问什么,也不知道怎么回答?
废话不多说,潘老师给大家梳理AP考试常见题型和解题思路,干货直接奉上!大腿赶紧抱起来,拒当炮灰!
近年来统计的题目考察知识点越来越细,对学生统计概念的考察难度也越来越大。因此要想拿到5分,对统计知识的理解绝对是要透彻、深刻。下面我们就来盘点选择题题型与常见的坑:
回顾历年题目,选择题常见的题型主要分为:
- 1. 图表判断、描述题(对应考点是统计各类图表的理解与描述)
- 2. 数据收集,样本分析以及实验设计(对应考点为数据收集)
- 3. 数据分析(对应考点包括Z-score, regression analysis)
- 4. 概率计算以及分布概率计算(对应考点为概率计算)
- 5. 置信区间概念与计算(对应考点为置信区间理解与计算)
- 6. 假设检验(对应考点为统计推断与p-value)
我们每个题型都进行分析,总结这类特点以及对应的思路策略
图表判断题给出的图表多为histogram, boxplot,scatter plot。不少同学可能忽略了另外一个图,叫cumulative frequency plot(累计频率图)。这个可能出现的考点是通过图来判断数据是skewed to left or right。例如,
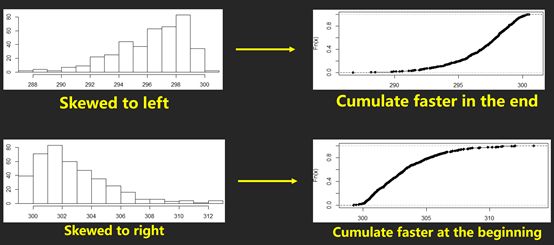
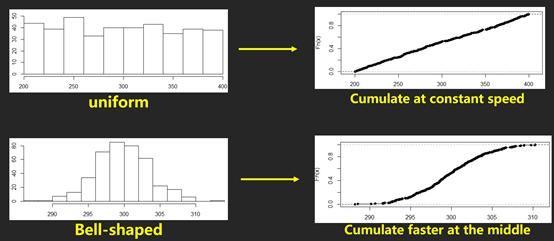
这类型的考点还会结合BOXPLOT,让你根据Q1,median以及Q3的位置判断数据的shape.
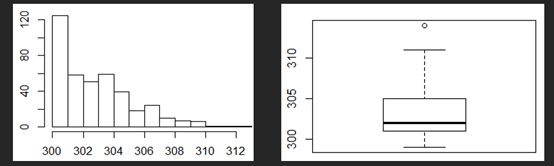
我们看这里,当skewed to the left,Q1与median的距离比median到Q3的距离近,说明数据集中在前面。
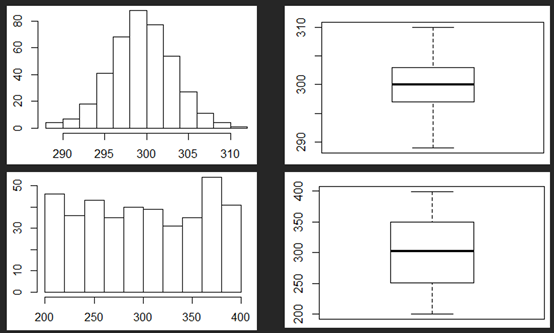
另外,题目可能会给boxplot Q1到median与median到Q3之间距离相等,让我们判断数据的shape。这种情况极有可能是bell-shape,也有可能会是uniform,所以大家要小心。
总体来说,这类题型相对比较简单,只要平时做好积累,仔细判断问题就不会太大。
考到数据收集和实验的题目,无外乎两点: 是不是足够random,是不是足够representative,可能存在的bias是什么。另外这类型题目考得最多的是区分observation study and experiment。大家只要注意出现assign,arrangement等干涉性的字眼,或者提到研究有人为分配东西给实验对象,这种就是experiment跑不了了。
数据分析部分的题目大部分会围绕regression进行考察。
这里,大家需要注意以下几个细节:
correlation coefficient的计算方式是x与y变量的z-score计算的,
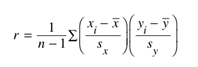
所以当x或y变量的单位改变时,他们的z-score不变,同时他们的r也是不会改变的。
我们看看这个例题:
Consider the following three scatterplots:
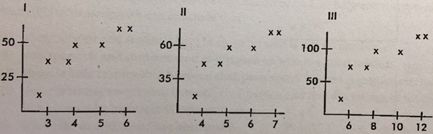
Which has the greatest correlation coefficient?
A. Ⅰ
B. Ⅱ
C. Ⅲ
D. They all have the same correlation coefficient
E. This question cannot be answered without additional information
例如这道题,大家注意看里面数据的点与scale的变化关系。这里相当于他们的测量单位变化了,但是他们的z-score还是恒定的,因此r算出来也是不变的。
第二个细节是![]() (coefficient of determination,也就是correlation coefficient r的平方)。这个大家都知道是proportionof variation of y explained by the regression model。但是这个proportion是什么呢?
(coefficient of determination,也就是correlation coefficient r的平方)。这个大家都知道是proportionof variation of y explained by the regression model。但是这个proportion是什么呢?
我们知道,在regression model中,, 因此,我们有
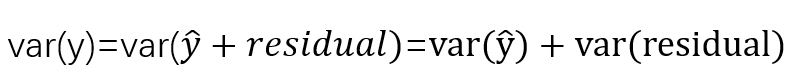
(因为与residual independent)。所以大家可以理解为
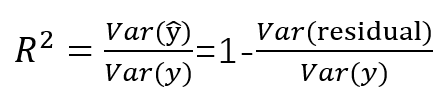
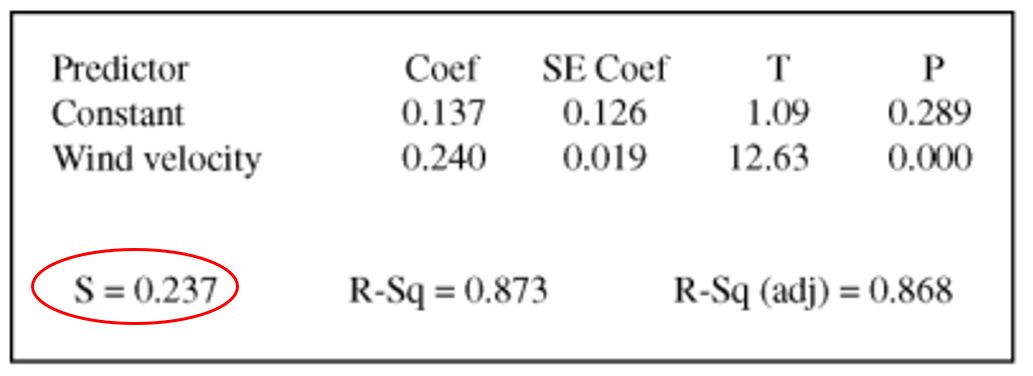
如果某道题给你var(residual),也就是大家常见的regression output table里面的 s,同时再给你var(y),问你如何计算![]() 。你只需要计算
。你只需要计算
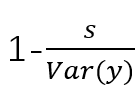 , 即可算出
, 即可算出![]()
第四部分的概率计算难点在于reversecondition probability,也就是公式的应用。
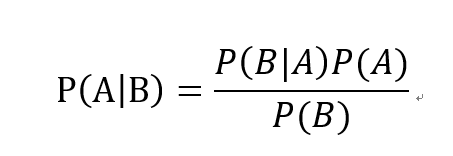

这道题就是典型的reverse conditionprobability题目。假设警报会响是T,不响是NT,有违禁品是C,没有违禁品是NC,那么题目要算的是P(C|T),给的条件是P(T|C)=97%, P(T|NC)=15%,P(C)=1/1000。根据公式,
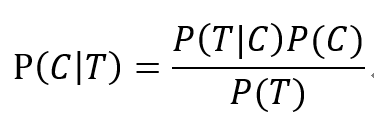
我们发现题目并没有P(T),怎么办?这也是所有这类题型的难点所在,常常是公式的分母需要在题目中挖掘和计算出来。
大家可以思考一下,警报会响,有可能是有违禁品,也有可能是没有违禁品。在这1000个包裹里,1个是含违禁品的,那么这1个包裹会响的个数就是1*P(T|C),而999个是没有的,那么他会响的个数就是999*P(T|NC),因此,会响的个数总共就是1*P(T|C)+999*P(T|NC)=150.82,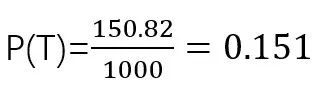 ,代进刚才的公式即可算出结果。
,代进刚才的公式即可算出结果。
对于置信区间,绝大部分的题目都是需要同学们进行计算,另外有些比较常见的题目会让大家计算至少需要多少样本数量才能让95%的margin of error 小于某个值。大家只要心中记好计算公式,带进去就可以了。
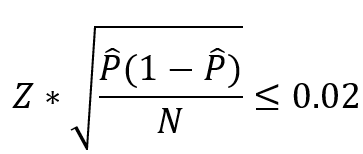
另外一种常见的考法是考察大家对不同的置信区间的用法以及对应的条件是什么。

总结起来就是,只要是proportion,那么一定用z-interval,如果是mean, 那么只要population standard deviation不知道就用t-interval。
千万把里面的公式与应用条件背熟!背熟!背熟!所有的选择题难点就是考察大家对公式的熟练程度。
另外还有关于regression的slope and intercept置信区间计算。
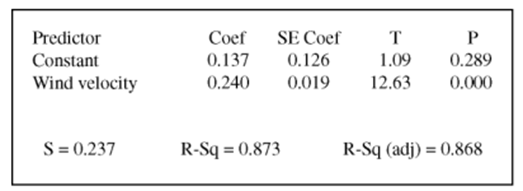
斜率的置信区间就是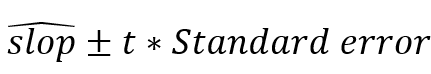 , 上面这个例子我们可以直接进行计算:
, 上面这个例子我们可以直接进行计算: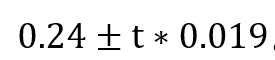 。这里的t取对应的confiden celevel和degree of freedom=n-2即可。
。这里的t取对应的confiden celevel和degree of freedom=n-2即可。
同理,intercept的置信区间为: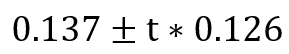
最后的hypothesis test与置信区间类似,要求大家计算test-statistics,所以关键的公式还是得背!得背!得背!对于不同的情况用什么test,与置信区间一样,只要是proportion,那么一定用z-test,如果是mean, 那么只要populationstandard deviation不知道就用t-test。




最后就是p-value的理解。P-value指的是,如果你的null hypothesis test是对的话,那么你做出来的sample mean(or proportion) 作为极端情况出现的概率。也就是说,如果我们假设中国人平均身高是170cm,你去做一个100人的抽样调查后,得到的平均身高是168cm。P-value指的就是如果咱们中国人平均身高真的就是170cm,你做出来这个168cm的样本,作为极端情况出现的概率时多少。假设是0.003,说明如果我们中国人平均身高真的是170cm的话,你能做出这个样本的概率只有0.003,那么说明中国人平均身高就非常不可能是170cm了。
好了,以上就是潘老师给大家带来的一点小分享。希望对大家有帮助,祝大家考出好成绩!
咨询或AP报名请添加顾问微信


翰林AMC8视频课重磅上线!

国际竞赛真题资源免费领取







