IB DP Biology: HL复习笔记7.3.4 Bioinformatics

Bioinformatics
- The 21st Century has seen a tremendous increase in the amount of biological data
- This has been due to rapid advances in DNA sequencing and other technologies
- Developments in scientific research have been accompanied by improvements in computing, enabling scientists to interpret complex biological data using bioinformatics applications
- Bioinformatics is an interdisciplinary field that develops methods and software to help further our understanding of life by making sense of this data
- Although many new bioinformatics applications are at the forefront of applied computing, most scientific research uses standard tools and databases
- Data related to gene sequence, protein structure, gene expression or metabolites is curated, annotated and stored in databases such as GenBank, NCBI, EBI, PDB
- A range of open source software tools is available to query this data
Sequence similarity
- If a scientist has an unknown DNA sequence, they can determine if it codes for a gene
- BLAST (Basic Local Alignment Search Tool) search can compare the unknown DNA sequence to all known gene sequences in a particular database
- BLAST finds regions of similarity between sequences
- The search returns ‘hits’ which are the sequences most related to the search sequence (depending on the parameters set)
- There are many variations of BLAST that can be used for different analyses such as protein sequences or comparing multiple input sequences at once
Genetic variation and evolutionary relationships
- Scientists can compare homologous gene sequences between many organisms
- Sequences are compared using an alignment tool such as Clustal W (there are many alternatives)
- This aligns (stacks) the sequences based on similar regions so that variable regions can be identified
- This determines the degree of similarity between organisms which gives an indication of how closely related the organisms are
- There may be a common ancestral origin but in some organisms, the gene might have accumulated differences over times from random mutations
- Tree-like evolutionary diagrams (phylogenetic trees) can be constructed with software such as PhyloWin to show the degree of relatedness to a recent common ancestor
- Phylogenetic analysis is useful for biological classification, conservation studies, forensics or molecular epidemiology which can help dictate public health policy
- Variants of highly infectious pathogens such as SARS-CoV-2 (a well-known coronavirus) can be identified using these techniques
Sequencing DNA to determine protein sequences
- The genetic code can be used to determine the amino acid sequence within a protein
- This primary structure information can be used to predict how proteins will fold into their tertiary structure
- This gives a greater level of understanding of how a protein functions or interacts with other proteins or molecules
- Such information can be used for a range of applications, such as drug design or novel protein engineering in synthetic biology
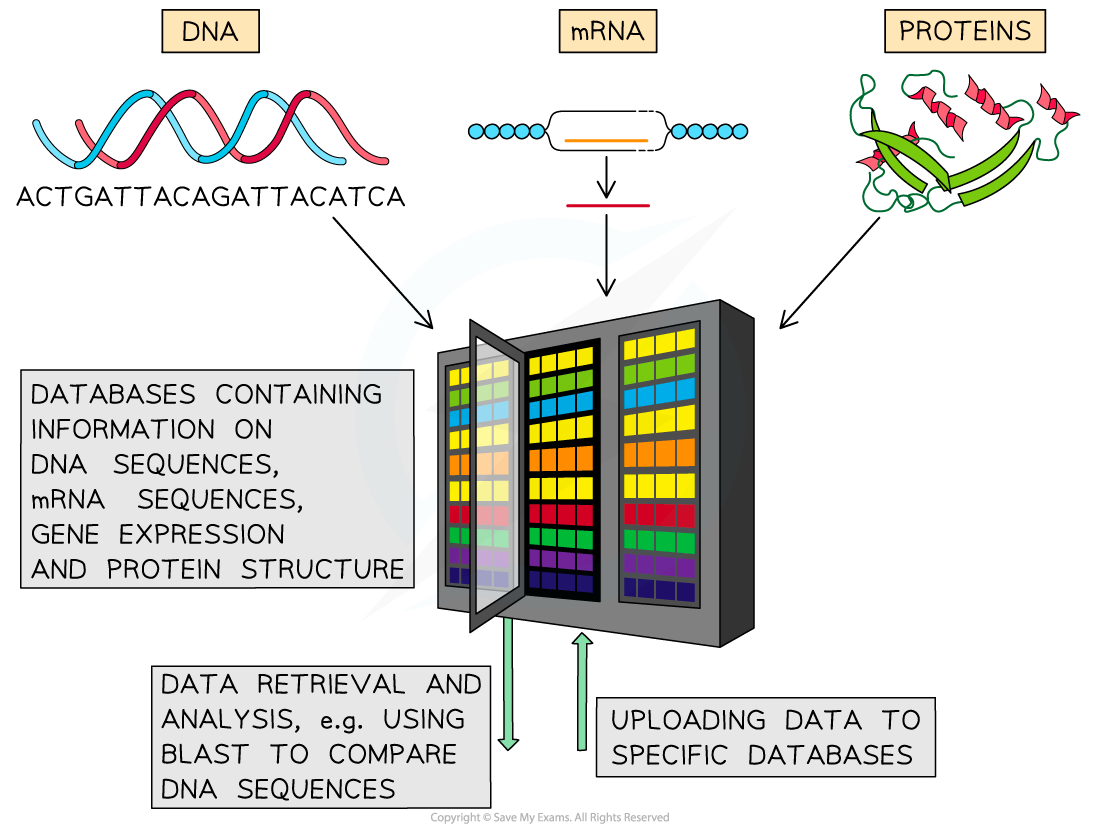
Bioinformatics allows for large amounts of biological data to be available instantly to researchers across the globe
转载自savemyexams
国际竞赛真题资料-点击免费领取!

早鸟钜惠!翰林2025暑期班课上线

美高学分项目重磅来袭!立即了解






