ICM实用模型及例题(E题)

2018/1/17周三国内常说的美国大学生数学建模学术活动,其实是由两种类型的学术活动组成,MCM即Mathematical Contest in Modeling,
直译为数学建模学术活动,和ICM即The Interdisciplinary Contest in Modeling,直译为交叉学科建模学术活动,两者名称不同,题目的风格有较大的差异。
ICM学术活动题目更开放,问题更“大”,更宏观,篇幅较长,往往是全球范围内共同关心的问题,因此一般不依赖特定的文化背景或生活习惯,近几年ICM学术活动要求论文正文部分不超过20页。
E题:environmental science
问题简介E题是环境科学问题,大体上会集中在环境污染、资源短缺、可持续发展、生态保护等几个方面。
环境与可持续发展是当今世界关注的重要议题,可持续发展的关键是协调好经济发展和环境保护之间的关系,这种协调有赖于应用系统论的观点研究环境系统内部各个组成部分和要素之间的对立统一关系;
也有赖于研究环境质量和社会经济发展的对立统一关系,建立最佳的经济结构和环境—经济布局,环境科学的发展给日益显现和加剧的环境问题的解决提供了重要方法和技术。
科学计算和数学模型的研究在环境科学研究和工作实践中占有重要地位,它是环境科学与其所依托的传统学科之间进一步交叉互动发展的需要,是量化认识、准确调控复杂环境系统的需要,也是环境科学研究的重要工具、环境规划、环境评价的核心技术之一。
今天我们主要介绍Entropy熵值法、AHP层次分析法和PCA主成分分析法三种方法。
Entropy 熵值法熵,英文为entropy,是德国物理学家克劳修斯在1850年创造的一个术语,它用来表示一种能量在空间中分布的均匀程度。
熵是热力学的一个物理概念,是体系混乱度(或无序度)的量度,用S表示。应用在系统论中,熵越大说明系统越混乱,携带的信息越少,熵越小说明系统越有序,携带的信息越多。
根据熵的特性,我们可以用熵值来判断某个指标的离散程度:指标熵值越小,离散程度越大,该指标对综合评价的影响(即权重)也就越大。
主要流程
Step1,确立指标体系
我们用手游认知客户挖掘模型实例来解说熵值法计算指标权重的全过程。下图是手游认知客户挖掘模型的二级指标评价体系,其中各个维度指标对应的权重系数均是通过熵值法计算出来的。
下面具体看下模型中 “手游认知能力”部分指标权重的计算过程。 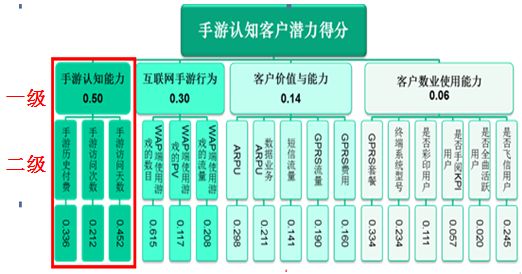
Step2,清洗指标极值方法:
即剔除各指标中极大或者极小的值,一般用比较合理的上下限值替换这些极值。目的是减少极值数据对该指标的熵的影响;
原则:剔除占样本总数不到1-2%但指标值贡献率超过20-30%以上的极值样本 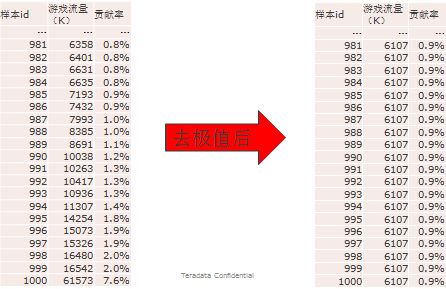 Step3,归一化指标处理方法:
Step3,归一化指标处理方法:
指标归一化过程也称之为指标的无量纲化,即将指标实际值转化为不受量纲影响的指标平价值。方法比较多,具体见附录《无纲量化方法一览》;
原则:比较常用的是临界值法和Z-score法(更合理,保持了数据的连续性,减少数据信息丢失),最终将所有指标转化为正区间里面,二者具体处理如下:  Step4,计算指标“熵”和“权”
Step4,计算指标“熵”和“权” 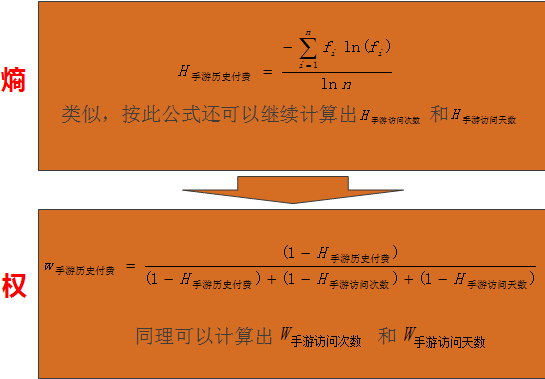
Step5,指标加权计算得分方法:
计算综合得分就是指标合成的过程,一般可以采用加法原理和乘法原理;
原则:最常用的是加法合成法,其具体处理如下:
利用以上3个指标的权重和归一化指标值,计算上级指标的分数:手游认知能力得分= 0.336*手游历史付费金额+0.212*手游访问次数 +0.452*手游访问天数。
当然,模型其他部分的底层指标权重和一级指标权重均可以按以上步骤计算得到,并一层层由下往上进行加权,最终得到模型的综合得分。
“AHP层次分析法层次分析法(AHP)是美国运筹学家匹茨堡大学教授萨蒂(T.L.Saaty)于上世纪70年代初,为美国国防部研究“根据各个工业部门对国家福利的贡献大小而进行电力分配”课题时,应用网络系统理论和多目标综合评价方法,提出的一种层次权重决策分析方法。
这种方法的特点是在对复杂的决策问题的本质、影响因素及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。层次
划分
最高层:决策的目的、要解决的问题
最低层:决策时的备选方案
中间层:考虑的因素、决策的准则
对于相邻的两层,称高层为目标层,低层为因素层
主要流程
建立层次结构模型
例如,假期旅游,是去风光秀丽的苏州,还是去凉爽宜人的北戴河,或者是去山水甲天下的桂林?通常会依据景色、费用、食宿条件、旅途等因素选择去哪个地方。 如何在3个目的地中按照景色、费用、居住条件等因素选择.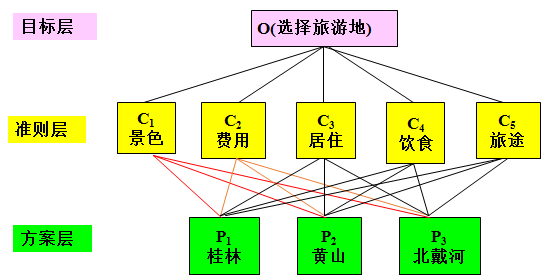 构造判断(成对比较)矩阵在建立递阶层次结构以后,上下层次之间元素的隶属关系就被确定了。假定上一层次的元素Ck作为准则,对下一层次的元素 A1, …, An 有支配关系,我们的目的是在准则 Ck 之下按它们相对重要性赋予 A1, …, An 相应的权重。比较同一层次中每个因素关于上一层次的同一个因素的相对重要性。
构造判断(成对比较)矩阵在建立递阶层次结构以后,上下层次之间元素的隶属关系就被确定了。假定上一层次的元素Ck作为准则,对下一层次的元素 A1, …, An 有支配关系,我们的目的是在准则 Ck 之下按它们相对重要性赋予 A1, …, An 相应的权重。比较同一层次中每个因素关于上一层次的同一个因素的相对重要性。
层次单排序及其一致性检验
一般地,我们并不要求判断具有这种传递性和一致性,这是由客观事物的复杂性与人的认识的多样性所决定的。
但在构造两两判断矩阵时,要求判断大体上的一致是应该的。出现甲比乙极端重要,乙比丙极端重要,而丙又比甲极端重要的判断,一般是违反常识的。
一个混乱的经不起推敲的判断矩阵有可能导致决策的失误,而且当判断矩阵过于偏离一致性时,用上述各种方法计算的排序权重作为决策依据,其可靠程度也值得怀疑。因而必须对判断矩阵的一致性进行检验。
定义一致性指标:![]() 有完全的一致性;CI接近于0,有满意的一致性;CI 越大,不一致越严重。
有完全的一致性;CI接近于0,有满意的一致性;CI 越大,不一致越严重。
定义一致性比率 :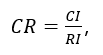 当CR<0.1时认为成对比矩阵的不一致程度在容许范围之内,有满意的一致性,通过一致性检验。层次总排序及其一致性检验
当CR<0.1时认为成对比矩阵的不一致程度在容许范围之内,有满意的一致性,通过一致性检验。层次总排序及其一致性检验
层次总排序的一致性比率:![]() 当CR<0.1时,认为层次总排序通过一致性检验。
当CR<0.1时,认为层次总排序通过一致性检验。
层次总排序具有满意的一致性,否则需要重新调整那些一致性比率高的判断矩阵的元素取值。“PCA主成分分析法主成分分析是把各变量之间互相关联的复杂关系进行简化的分析方法。
在社会经济的研究中,为了全面系统的分析和研究问题,必须考虑许多经济指标,这些指标能从不同的侧面反映我们所研究的对象的特征,但在某种程度上存在信息的重叠,具有一定的相关性。
主成分分析试图在力保数据信息丢失最少的原则下,对这种多变量的截面数据表进行最佳综合简化,也就是说,对高维变量空间进行降维处理。
主要流程
对原始数据进行标准化
计算相关系数矩阵
计算特征值与特征向量
计算主成分载荷
各主成分的得分
几何解释
假设我们所讨论的实际问题中,有p个指标,我们把这p个指标看作p个变量,记为X1,X2,…,Xp,主成分分析就是要把这p个指标的问题,转变为讨论p个指标的线性组合的问题,而这些新的指标F1,F2,…,Fk(k≤p),按照保留主要信息量的原则充分反映原指标的信息,并且相互独立。 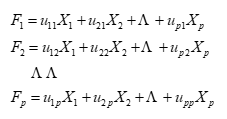
国际竞赛真题资料-点击免费领取!

早鸟钜惠!翰林2025暑期班课上线

美高学分项目重磅来袭!立即了解






