ICM实用模型及例题(D题)

国内常说的美国大学生数学建模学术活动,其实是由两种类型的学术活动组成,MCM即Mathematical Contest in Modeling,直译为数学建模学术活动,和ICM即The Interdisciplinary Contest in Modeling,直译为交叉学科建模学术活动,两者名称不同,题目的风格有较大的差异。ICM学术活动题目更开放,问题更“大”,更宏观,篇幅较长,往往是全球范围内共同关心的问题,因此一般不依赖特定的文化背景或生活习惯,近几年ICM学术活动要求论文正文部分不超过20页。
D题:operations research/network science 问题简介
自2016年开始,ICM由原来的一道题增至三道题,一般为D题、E题、F题,分别为operations research/network science、environmental science和policy这三种类型。首先我们介绍一下D题也就是operations research/network science这个部分。
D题一般是运筹学和网络科学的问题,所用到模型、算法、软件比较集中,有章可循。运筹学是以整体最优为目标,从系统的观点出发,力图以整个系统最佳的方式来解决该系统各部门之间的利害冲突的一门学科。它对所研究的问题求出最优解,寻求最佳的行动方案,所以它也可看成是一门优化技术,提供的是解决各类问题的优化方法。
而网络科学是近几年的一个热门研究领域,比如著名的“哥尼斯堡七桥”问题,其实就是网络科学较早的实际问题,欧拉在1736年用抽象分析法解决了这个问题,这也使欧拉成为图论〔及拓扑学〕的创始人。如果对求解最优解问题和图论问题感兴趣,或者对这些领域的相关知识和软件都比较熟悉,选题时可以重点关注D题。今天我们首先介绍这道题常用的四种数学模型,分别是Programming数学规划、complex network复杂网络、Queuing排队论和Clustering聚类分析。
Programming 数学规划
一般地,优化模型可以表述如下: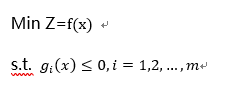
这是一个多元函数的条件极值问题,其中 x = [ x 1 , x 2 , … , x n ]。许多实际问题归结出的这种优化模型,但是其决策变量个数 n 和约束条件个数 m 一般较大,并且最优解往往在可行域的边界上取得,这样就不能简单地用微分法求解,数学规划就是解决这类问题的有效方法。三要素:决策变量、目标函数、约束条件适用场景:
1.实际对象特征间及特征与环境间的交互不存在非线性关系的优化问题
2.需利用非线性刻画对限制条件或当前局势进行描述的优化问题
3.决策控制域离散且域中相邻两个元素间测度相等的优化问题
4.需在多个目标间进行权衡达到整体局势最优的优化问题
5.以时间划分阶段的动态过程的优化问题
建模步骤:
Step 1. 寻求决策,即回答什么?必须清楚,无歧义。
Step 2. 确定决策变量
第一来源:Step 1的结果,用变量固定需要回答的决策
第二来源:由决策导出的变量(具有派生结构)
其它来源:辅助变量(联合完成更清楚的回答)
Step 3. 确定优化目标
用决策变量表示的利润、成本等。
Step 4. 寻找约束条件
决策变量之间、决策变量与常量之间的联系。
第一来源:需求;
第二来源:供给;
其它来源:辅助以及常识。
Step 5. 构成数学模型
将目标以及约束放在一起,写成数学表达式。常见类型:
线性规划 (目标函数及约束条件均为线性函数)
整数规划 (决策变量部分或全部被限制为整数)
多目标规划 (具有多于一个的目标函数)
动态规划(把多阶段过程转化为一系列单阶段问题,逐个求解)
complex network 复杂网络
在我们的现实生活中,许多复杂系统都可以建模成一种复杂网络进行分析,比如常见的电力网络、航空网络、交通网络、计算机网络以及社交网络等等。具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质的网络称之为复杂网络,言外之意,复杂网络就是指一种呈现高度复杂性的网络。
适用场景l社团检测:潜在客户挖掘、关联群体风险分析等;l网络中心性分析:网页排名(PageRank),供应链核心企业识别,信息传播枢纽节点识别等;网络传播预测:流行病传播,金融风险传播,舆论传播;
网络关系渗透:节点之间的关系(三度影响);
关联交易分析及投融资黑洞:虚假交易,担保圈分析等。
基本概念
l节点、边
l关联与邻接
l度 k、平均度 <k>
l节点的度分布p(k)
l最短路径与平均路径长度(Dijkstra算法)
常用网络
ER模型:Erdös和Rényi (ER)最早提出随机网络模型并进行了深入研究,他们是用概率统计方法研究随机图统计特性的创始人。给定N个节点,没有边,以概率p用边连接任意一对节点,用这样的方法产生一随机网络。
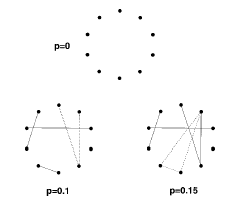
节点的度分布:平均值为的泊松分布小世界模型: 为了描述从一个局部有序系统到一个随机网络的转移过程,Watts和 Strogatz(WS)提出了一个新模型,通常称为小世界网络模型。WS模型始于一具有N个节点的一维网络,网络的节点与其最近的邻接点和次邻接点相连接,然后每条边以概率p重新连接。
约束条件为节点间无重边,无自环。当p等于0时,对应于规则图。两个节点间的平均距离<L>线性地随N增长而增长,集聚系数大。当p等于1时,系统变为随机图。 <L>对数地随N增长而增长,且集聚系数随N减少而减少。
在p等于(0,1)区间任意值时,<L>约等于随机图的值,网络具有高度集聚性---小世界效应。
无标度(Scale-free)网络: 无标度模型由Albert-László Barabási和Réka Albert在1999年首先提出,现实网络的无标度特性源于众多网络所共有的两种生成机制:(ⅰ)网络通过增添新节点而连续扩张; (ⅱ)新节点择优连接到具有大量连接的节点上。
具有性质:度分布呈幂率分布、中枢节点出现、鲁棒性、脆弱性。
Queuing 排队论
面对拥挤现象,人们总是希望尽量设法减少排队,通常的做法是增加服务设施,但是增加的数量越多,人力、物力的支出就越大,甚至会出现空闲浪费,如果服务设施太少,顾客排队等待的时间就会很长,这样对顾客会带来不良影响。顾客排队时间的长短与服务设施规模的大小,就构成了设计随机服务系统中的一对矛盾。
如何做到既保证一定的服务质量指标,又使服务设施费用经济合理,恰当地解决顾客排队时间与服务设施费用大小这对矛盾。这就是随机服务系统理论——排队论所要研究解决的问题。适用场景排队论里把要求服务的对象统称为“顾客”,而把提供服务的人或机构称为“服务台”或“服务员”。不同的顾客与服务组成了各式各样的服务系统。顾客为了得到某种服务而到达系统、若不能立即获得服务而又允许排队等待,则加入等待队伍,待获得服务后离开系统。
主要流程
l 确定时间分布(到达时间和服务时间)
l 研究系统理论分布的概率特征
l 研究系统状态的概率
l 求解概率分布和特征数
l 指标优化与运营优化
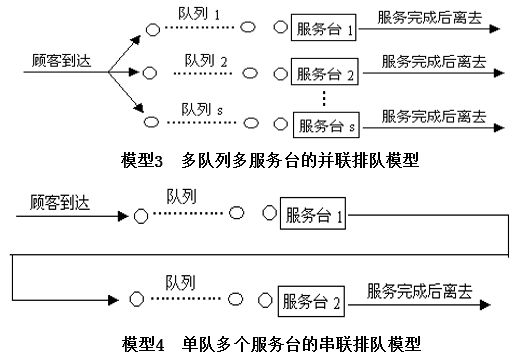
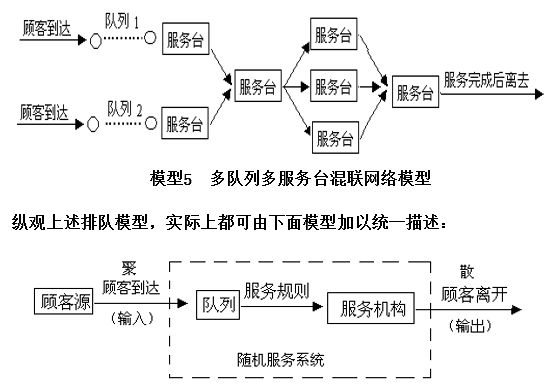
排队模型
根据顾客到达和服务台数,排队过程可用下列模型表示: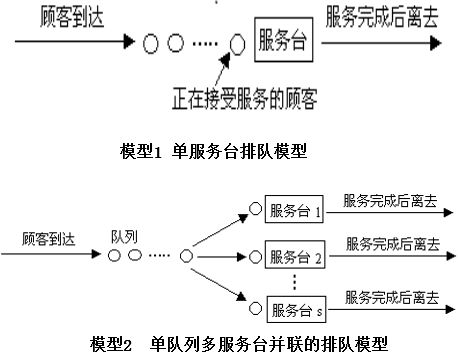
Clustering 聚类分析
聚类分析顾名思义是一种分类的多元统计分析方法。按照个体或样品的特征将它们分类,使同一类别内的个体具有尽可能高的同质性,而类别之间则应具有尽可能高的异质性。
常见类型l划分
聚类 k-means、k-medoids、k-modes、k-medians、kernel k-mea
层次聚类 Agglomerative 、divisive、BIRCH、ROCK、Chameleo
密度聚类 DBSCAN、OPTICS
网格聚类 STING
模型聚类 GMM
图聚类 Spectral Clustering(谱聚类)偏最小二乘回归
主要流程
1.对数据进行变换处理;(不是必须的,当数量级相差很大或指标变量具有不同单位时是必要的)
2.构造n个类,每个类只包含一个样本;
3.计算n个样本两两间的距离;
4.合并距离最近的两类为一新类;
5.计算新类与当前各类的距离,若类的个数等于1,转到6;否则回4;
6.画聚类图;
7.决定类的个数,从而得出分类结果。指标优化与运营优化
常见距离度量
国际竞赛真题资料-点击免费领取!

美高学分项目重磅来袭!立即了解

2025欧几里得数学竞赛报名开启!





