从数据中发现隐藏价值之CV/NLP方向

CV方向
徐光福 ID:天灵灵地灵灵
简介:多次目标检测比赛第一、2018之江杯VQA比赛第二。
对于挖掘类的比赛来说,数据探索非常重要,涉及的方方面面很多 (反正我也不知道有哪些方面),但是对于图像类比赛来说,数据探索就相对简单一些,依然以基于虚拟仿真环境下的自动驾驶交通标志识别https://www.datafountain.cn/competitions/339这个比赛为例,讲一下计算机视觉类比赛的数据探索。
对于计算机视觉类比赛,数据探索主要是了解数据集的属性、特点,以及如何进行一些数据预处理,例如图像格式转换,生成数据字典等等,为之后的数据加载做好准备。
首先我们看一下交通标志识别比赛的数据集:
1. 训练集和测试集都有大约20000张图片,格式为JPG
训练集和测试集都有两万张图片,在一般的比赛中应该属于比较多的了,当然和coco、objects365之类的数据集没法比,格式为JPG,不像某些医疗影像的比赛,还需要做特别的格式甚至坐标的转换,这里不需要,算是一个不错的开端
2. 训练集和测试集的图像大小都为固定大小,3200x1800
图像大小固定,这也是一个好消息,相比图像大小不一、纵横比也很随意的数据集来说好处理不少。但是,图片大小3200x1800,就有点不一般了,前面说了,这是一个目标检测比赛,这么大的图是很难直接加载并训练的。
面对这种大图,通常我们有两种选择:缩图和裁剪
缩小图像对比赛尤其是目标检测比赛来说,通常不是一个好选择,因为无数经验表明,图大往往是提高目标检测成绩的最简单最有效的选择。能原图训练就不要缩小,如果能比原图还大,那通常也是不错的选择,很少有例外;通常不是好选择也不意味着就不能用,在没有其它好的办法的情况下,缩图也是可以接受的,总之有点像无奈的选择
再说说裁剪,裁剪意味着可以用很小的尺寸实现近似原图训练的效果,从这点上来说,他比起缩图确实是占有优势的,缺点是处理起来比较麻烦,有时候甚至是很难处理,比如目标比较密集,很容易就把很多目标切的七零八落。所以缩图还是裁剪,还是要根据数据集的特点来选择
3. 无论训练集和测试集每张图片都固定有一个、且只有一个目标
这简直是福音了,每张图片只有一个目标,这裁剪起来就方便了很多,所以在缩图和裁剪这个问题上就不用纠结了,选择裁剪吧。对于这种单目标的数据集来说,一个很好的选择就是围绕目标进行随机裁剪,而且最好是以online的方式进行,这样每次裁剪出的东西都不一样,极大的增加了样本的数量。
4. 目标为交通标志,一共有20类,其中有左侧行驶、右侧行驶这类左右对称的目标
这个没什么好说的,目标相对来说比较好识别,需要注意的是既然有左右对称的目标,就不能直接使用左右翻转的数据增强了,当然也可以进行一下特别的处理,比如翻转后调整相应的类别标签
5. 提供的训练集标注为csv格式,每个目标一行
对于目标检测来说,一般要把标注转换为coco的格式,这通常也是代码的第一步,至于如何转换,首先需要熟悉一下coco的格式,代码方面并没有什么难度
数据探索完成之后,已经基本了解了数据集的属性和特点,就可以开始代码的工作了,先尝试把数据集的标注转换为coco的格式,迈出代码的第一步吧~ 王博 ID:000wangbo
简介:西安电子科技大学研究生,一个不断在CV道路上探索的小白。
数据探索在数据挖掘比赛中是特别重要的一部分。如果把我们的模型当作柯南,那我们喂进去的数据就是柯南的破案线索,而破案线索并不会简简单单越多越好 (数据清洗),柯南选择通过毛利小五郎或者服部平次揭开真相的方式也不同 (模型、超参数选择)。
机器学习类比赛数据探索一般包含缺失值处理、异常值处理、转非数以及绘制关联热力图等等。不过今天作为cv方向嘉宾,那我就从一个比赛导入下如何通过数据探索拿下Top。比赛地址:
https://www.datafountain.cn/competitions/315解题方案:
https://zhuanlan.zhihu.com/p/51870164周易大佬的知乎,强推一波,里面有很多大赛的开源赛题任务
天空的薄云,往往是天气晴朗的象征;而那些低而厚密的云层,常常是阴雨风雪的预兆。我们希望选手基于大赛提供的海量云彩图片,通过深
度学习训练模型,识别图片中不同类型的云彩,预测大赛提供的测试云彩图片。
这是个比较明显的五分类的比赛,评价指标是五类F1-score的均值。很多人看到这个题目,就赶紧上个五分类模型跑一哈然后各种数据增强模型融合,可能前期确实能在前排,但是最终一定拿不到Top。那我们开始数据探索,首先我们能看到这个数据的样本不平衡,那就通过crop上采样一些小样本;
然后我们通过比较图片的MD5值,发现竟然有好多重复的图片,有一些的label还是矛盾的,清洗清洗!最终我们发现了一个惊天漏洞,test中的图片还有大约100张左右和train里面是一样的。
通过数据中的这些trick,我们做了不到10天就拿到了亚军,足以看出数据探索在比赛中的重要程度了吧!最终,分享下最近一个遥感分类比赛的数据trick(通过排序能够看到很多全黑图片和异常图片):http://rscup.bjxintong.com.cn/#/theme/1

NLP方向
张浩 ID:reborn_ZH
简介:CCF2018供应链需求预测亚军、2019搜狐内容识别算法大赛季军。
大家好,本期我将和大家交流下自然语言处理赛题的数据探索部分,为了更好地与实战接轨,后面的部分我都将以2019年搜狐内容识别算法大赛为例进行讲解。
比赛链接:2019年搜狐内容识别算法大赛
赛题任务
给定若干文章,目标是判断文章的核心实体以及对核心实体的情感态度。每篇文章识别最多三个核心实体,并分别判断文章对上述核心实体的情感倾向(积极、中立、消极三种)。
评价指标
模型得分的计算方式:
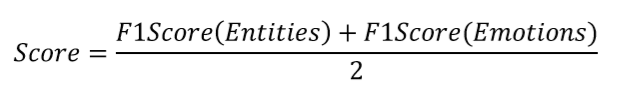
分数由实体词的F1-score以及实体情感的F1-score组成,每个样本计算micro F1-Score,然后取所有样本分数的平均值。
实体词的F1-score如下:
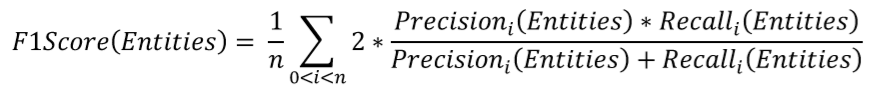
实体情感的F1-score由实体_情绪的组合标签进行判断,只有实体情绪都正确才算正确的标签。
实体情感的F1-score如下:
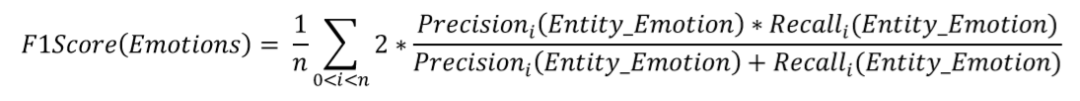
赛题数据

数据可视化
数据可视化作为数据探索中非常重要的一步,我们利用视觉获取的信息量,远远比别的感官要多得多。通过图形和色彩将关键数据和特征直观地传达出来,从而实现对于复杂的数据的深入洞察。数据可视化则是通过一目了然地方式,获得客观数据层面的引导或者验证。
首先,我们对训练集长度、实体词位置、热点词进行可视化,帮助我们了解训练集的基本信息和数据分布。
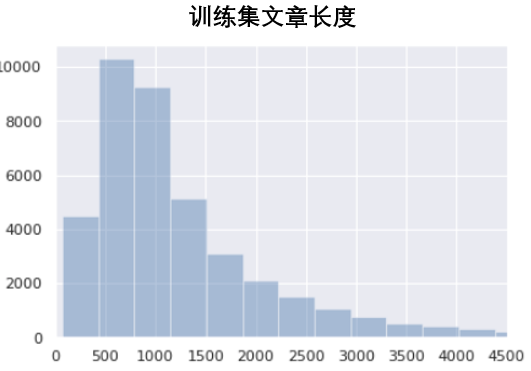
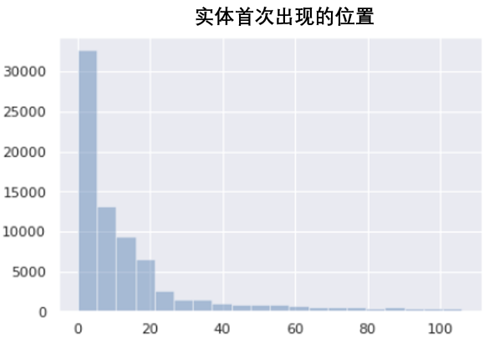

从上面3个图中可以得知,训练集的样本长度主要集中在500到1000之间,并且大多数样本的实体词在前几个词中就会出现。
接下来,我们对实体词进行更细致的统计分析,这有利于帮助我们理解数据,便于我们后面对数据进行处理。
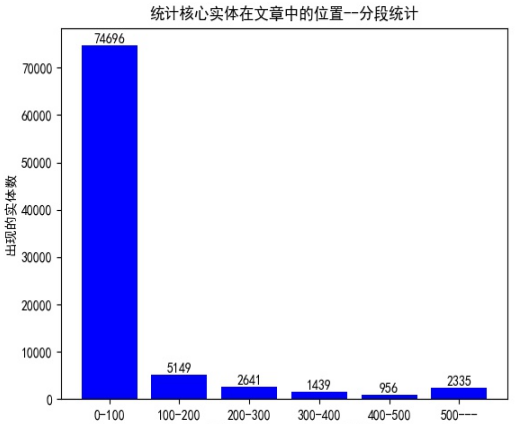
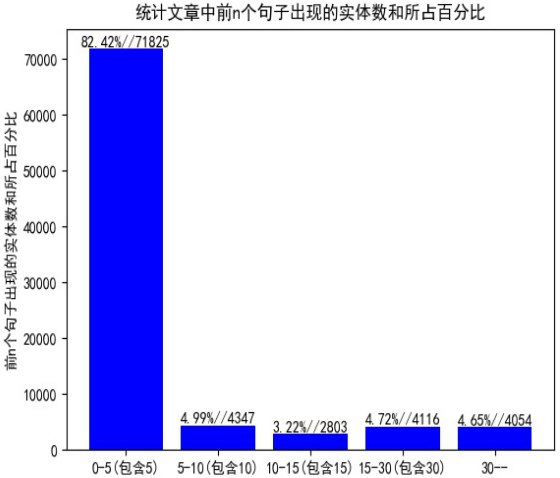
统计核心实体在新闻中出现的位置,在第0-100个索引(字)之间有74696个核心实体,100-200有5149个,以此类推。说明在识别实体的时候重点要放在文章的前部半分,不必分析整篇文章。分析前n个句子中出现的核心实体数以及占总实体数的百分之多少,前五个句子中出现了的核心实体数占所有实体数的80%多。说明我们只要将前几句输入到模型训练就可得到很好的效果。

翰林AMC8视频课重磅上线!

国际竞赛真题资源免费领取







